AI Sales Coaching: Real-Time Call Analysis with Claude Code & Codex [2026]
The brutal truth about sales coaching: Managers don't have time for it.
With 8-12 direct reports, each making 50+ calls per week, there's no way to review more than a tiny sample. So coaching becomes reactive—triggered by lost deals rather than prevented by proactive skill development.
Meanwhile, your competitors are using AI to analyze every call, provide instant feedback, and ramp new reps 40% faster.
Let me show you how to build that system.
Why Traditional Sales Coaching Fails
Let's be honest about the problems:
1. It's a sampling problem A manager who reviews 5 calls per rep per month is missing 95%+ of coaching opportunities. The deals that slip through? Never analyzed.
2. Feedback is delayed By the time a manager reviews a call, the rep has already moved on. Context is lost. Habits are reinforced.
3. It's subjective Different managers coach differently. What's "good" varies by opinion. Reps get confused by conflicting feedback.
4. No pattern recognition Humans can't track whether a rep is improving on objection handling over 6 months. They rely on gut feel.
AI solves all four:
- Every call analyzed (no sampling)
- Instant feedback (while context is fresh)
- Objective criteria (consistent standards)
- Pattern tracking (data-driven coaching plans)
The AI Coaching Framework
An intelligent coaching system does four things:
- Transcribes and analyzes every call
- Scores against defined criteria objectively
- Delivers instant feedback to reps
- Tracks improvement trends over time
Let's build each piece.
Step 1: Call Analysis with Claude Code
Claude's 200K context window is perfect for analyzing full sales conversations. Here's the analysis framework:
# Sales call analysis with Claude Code
async def analyze_sales_call(transcript, call_metadata):
"""
Comprehensive analysis of a sales call using Claude
"""
analysis_prompt = f"""
Analyze this sales call transcript and provide structured coaching feedback.
CALL METADATA:
- Rep: {call_metadata['rep_name']}
- Prospect: {call_metadata['prospect_name']} ({call_metadata['prospect_title']})
- Company: {call_metadata['company_name']}
- Stage: {call_metadata['deal_stage']}
- Duration: {call_metadata['duration_minutes']} minutes
TRANSCRIPT:
{transcript}
ANALYZE THE FOLLOWING DIMENSIONS:
1. DISCOVERY QUALITY (0-100)
- Did rep ask open-ended questions?
- Did rep uncover pain points?
- Did rep understand decision process?
- Did rep identify other stakeholders?
2. TALK RATIO (0-100, 30-40% rep talk time is ideal)
- Calculate approximate rep vs prospect talk time
- Was rep listening or lecturing?
3. OBJECTION HANDLING (0-100)
- Were objections acknowledged?
- Did rep use empathy before responding?
- Was the response relevant to the objection?
- Did rep confirm resolution?
4. VALUE ARTICULATION (0-100)
- Did rep connect features to prospect's specific pain?
- Was ROI or business case discussed?
- Were relevant case studies/proof points used?
5. NEXT STEPS (0-100)
- Was a clear next step established?
- Were specific date/time confirmed?
- Was next step tied to prospect's timeline?
6. PROFESSIONALISM (0-100)
- Appropriate energy level?
- Professional language?
- Respect for prospect's time?
For each dimension, provide:
- Score (0-100)
- 1-2 specific examples from the transcript (quote directly)
- 1 actionable coaching point
Also identify:
- The single biggest opportunity for improvement
- One thing the rep did exceptionally well
- Any red flags for this deal
Format as JSON.
"""
response = await claude.generate(
prompt=analysis_prompt,
model='claude-3-opus',
response_format='json'
)
return parse_analysis(response)
Example output:
{
"discovery_quality": {
"score": 72,
"examples": [
"Rep asked 'What's driving this evaluation?' - good open-ended question",
"Missed opportunity to dig into 'We've tried other tools' - didn't ask what failed"
],
"coaching_point": "When prospect mentions past solutions, always ask 'What didn't work about that?' to understand deeper pain"
},
"talk_ratio": {
"score": 45,
"actual_ratio": "55% rep / 45% prospect",
"coaching_point": "You're talking slightly more than ideal. Try pausing 2-3 seconds after prospect answers before responding."
},
"objection_handling": {
"score": 65,
"examples": [
"When prospect said 'budget is tight', rep immediately jumped to discounting",
"Didn't acknowledge the concern before responding"
],
"coaching_point": "Use the Feel-Felt-Found framework: 'I understand budget is a concern. Other [similar companies] felt the same way. What they found was...'"
},
"biggest_opportunity": "Discovery was surface-level. Rep got answers but didn't dig into the 'why' behind them. More follow-up questions needed.",
"exceptional_moment": "Great job summarizing the prospect's situation at the 12-minute mark. Shows active listening.",
"deal_red_flags": ["Prospect mentioned 'need to check with team' twice - multiple stakeholders not yet identified"]
}
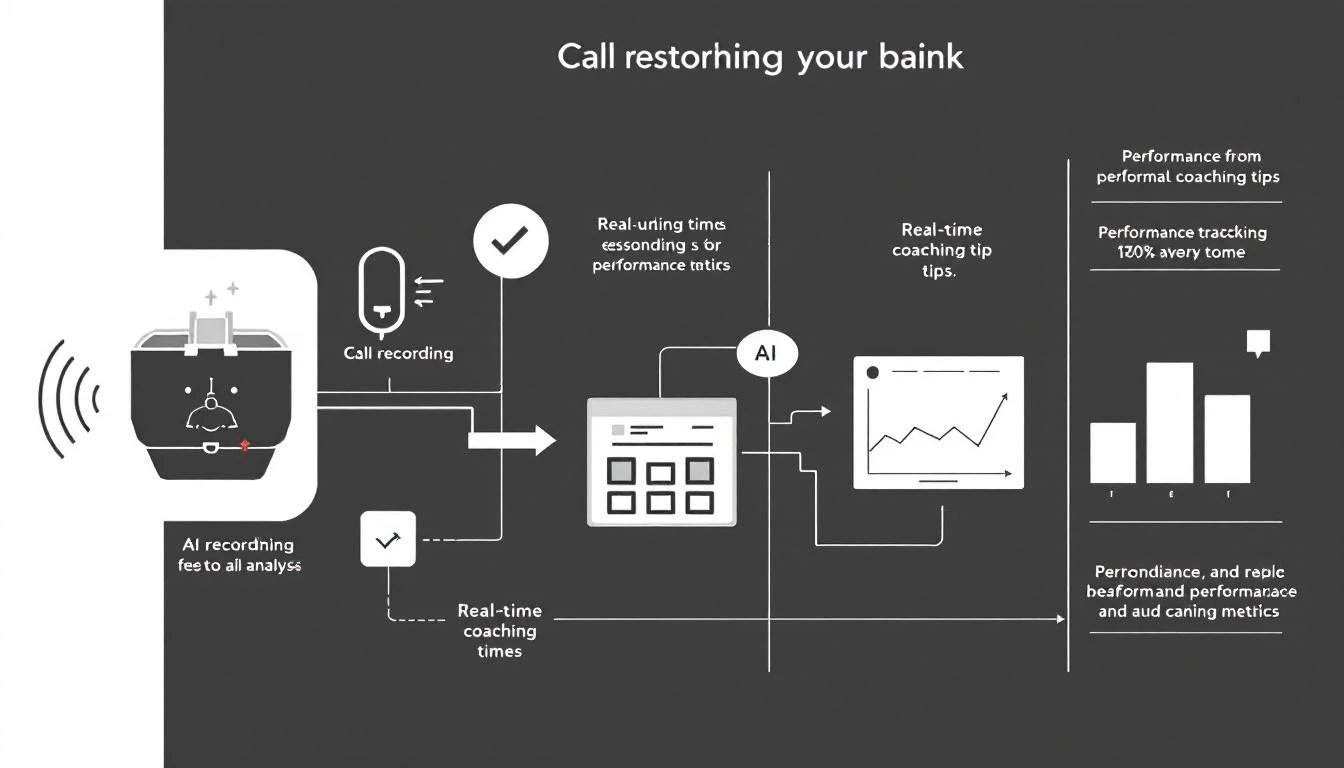
Step 2: Real-Time Feedback Delivery
The key to effective coaching is timing. Feedback delivered within 30 minutes of a call is 5x more effective than next-day reviews.
# Real-time feedback automation with OpenClaw
trigger: call_ended
workflow:
- step: transcribe
action: fetch_transcript
source: gong_or_zoom_or_dialpad
- step: analyze
action: run_claude_analysis
prompt_template: sales_call_analysis
- step: deliver_feedback
action: send_to_rep
channel: slack_dm
template: |
📞 **Call Review: \{prospect_name\}**
**Overall Score:** {average_score}/100
**Quick Wins:**
✅ {exceptional_moment}
**Focus Area:**
🎯 {biggest_opportunity}
**Key Coaching Points:**
{coaching_points_summary}
[View Full Analysis →]({analysis_link})
- step: update_metrics
action: store_in_database
table: rep_call_scores
Step 3: Objective Scoring Criteria with Codex
Use Codex GPT-5.3 to build consistent scoring rubrics:
// Scoring rubric generator using Codex
// Ensures consistent criteria across all calls
const SCORING_RUBRICS = {
discovery_quality: {
excellent: {
min: 85,
criteria: [
'Asked 5+ open-ended questions',
'Uncovered primary and secondary pain points',
'Identified decision makers and influencers',
'Understood timeline and urgency drivers',
'Explored budget and past solutions'
]
},
good: {
min: 70,
criteria: [
'Asked 3-4 open-ended questions',
'Uncovered primary pain point',
'Identified main decision maker',
'Basic understanding of timeline'
]
},
needs_improvement: {
min: 50,
criteria: [
'Asked 1-2 open-ended questions',
'Surface-level pain understanding',
'Did not map decision process'
]
},
poor: {
min: 0,
criteria: [
'Mostly closed questions or none',
'Jumped to pitch without discovery',
'No understanding of prospect situation'
]
}
},
objection_handling: {
excellent: {
min: 85,
criteria: [
'Acknowledged objection with empathy',
'Asked clarifying question',
'Provided relevant response with proof',
'Confirmed resolution before moving on',
'Turned objection into opportunity'
]
},
good: {
min: 70,
criteria: [
'Acknowledged objection',
'Provided reasonable response',
'Moved forward appropriately'
]
},
needs_improvement: {
min: 50,
criteria: [
'Responded but didn\'t acknowledge',
'Generic response not tied to objection',
'Didn\'t confirm resolution'
]
},
poor: {
min: 0,
criteria: [
'Ignored or argued with objection',
'Became defensive',
'Lost control of conversation'
]
}
}
// ... additional rubrics
};
function scoreAgainstRubric(dimension, examples) {
// Codex can generate the matching logic
// to consistently apply rubrics
}
Step 4: Trend Tracking and Coaching Plans
Individual call feedback isn't enough. You need to track improvement over time:
# Rep improvement tracking
def generate_coaching_plan(rep_id, lookback_days=30):
"""
Analyzes rep's calls over time and generates targeted coaching plan
"""
# Get all call scores in period
call_scores = get_rep_call_scores(rep_id, lookback_days)
# Calculate dimension trends
trends = {}
for dimension in SCORING_DIMENSIONS:
scores = [c[dimension] for c in call_scores]
trends[dimension] = {
'average': sum(scores) / len(scores),
'trend': calculate_trend(scores), # improving, flat, declining
'variance': calculate_variance(scores),
'lowest_call': min(call_scores, key=lambda x: x[dimension]),
'highest_call': max(call_scores, key=lambda x: x[dimension])
}
# Identify priority areas
priority_areas = sorted(
trends.items(),
key=lambda x: x[1]['average']
)[:2] # Bottom 2 dimensions
# Generate coaching plan
coaching_plan = {
'rep_id': rep_id,
'period': f'{lookback_days} days',
'calls_analyzed': len(call_scores),
'overall_trend': 'improving' if average_improving(trends) else 'needs_attention',
'priority_focus_areas': [
{
'dimension': area[0],
'current_average': area[1]['average'],
'target': area[1]['average'] + 10, # 10-point improvement goal
'example_good_call': get_example_call(rep_id, area[0], 'high'),
'example_area_for_growth': get_example_call(rep_id, area[0], 'low'),
'recommended_training': get_training_module(area[0])
}
for area in priority_areas
],
'strengths': [
{
'dimension': dim,
'average': data['average']
}
for dim, data in trends.items()
if data['average'] >= 80
],
'next_review_date': calculate_next_review(trends)
}
return coaching_plan
Example coaching plan output:
Rep: Sarah Chen
Period: 30 days
Calls Analyzed: 47
Overall: Improving 📈
Priority Focus Areas:
1. Objection Handling (avg: 62/100)
- Target: 72/100
- Training: "Feel-Felt-Found Framework" module
- Example high: Call with Acme Corp on Jan 15 (78)
- Example growth: Call with Widget Inc on Jan 22 (48)
2. Discovery Quality (avg: 68/100)
- Target: 78/100
- Training: "SPIN Selling Deep Dive" module
- Example high: Call with TechStart on Jan 28 (85)
- Example growth: Call with MegaCorp on Jan 19 (52)
Strengths:
- Professionalism (avg: 92) 🌟
- Next Steps (avg: 85) 🌟
Next Review: February 15
Implementing AI Coaching: Practical Steps
For Small Teams (< 10 reps)
# Lightweight implementation
stack:
- transcription: Fireflies.ai or Otter.ai
- analysis: Claude API
- delivery: Slack DM
- tracking: Spreadsheet or Notion
workflow:
1. Rep ends call
2. Transcription automatically generated
3. Cron job runs Claude analysis every 2 hours
4. Feedback delivered to Slack
5. Weekly scores aggregated in tracking sheet
For Larger Teams (10-50+ reps)
# Full implementation
stack:
- transcription: Gong, Chorus, or Clari
- analysis: Claude API + custom Codex scoring
- delivery: Slack + CRM integration
- tracking: Dedicated coaching dashboard
- automation: OpenClaw for orchestration
workflow:
1. Call recorded in Gong
2. Webhook triggers OpenClaw
3. Analysis runs immediately
4. Feedback to rep in < 30 minutes
5. Scores logged to dashboard
6. Weekly coaching reports auto-generated
7. Manager alerts for declining trends
Measuring Coaching Impact
Track these metrics to prove ROI:
| Metric | What It Shows | Target |
|---|---|---|
| Ramp time to quota | How fast new reps become productive | Reduce 20-40% |
| Call score improvement | Are reps actually getting better? | 5+ points/month |
| Conversion rate by score | Does higher score = more deals? | Positive correlation |
| Coaching engagement | Are reps reading feedback? | > 80% open rate |
| Manager time saved | Efficiency gain | 5+ hours/week |
The Human Element
AI coaching doesn't replace managers. It amplifies them.
Before AI:
- Manager reviews 5% of calls
- Feedback is subjective and inconsistent
- Coaching is reactive to problems
With AI:
- AI analyzes 100% of calls
- Scores are objective and consistent
- Manager focuses on high-impact coaching conversations
- Coaching is proactive and data-driven
The manager's role shifts from "call reviewer" to "coach"—using AI insights to have better, more targeted conversations with their team.
Quick Start Checklist
Week 1: Foundation
- Choose transcription solution
- Set up Claude API access
- Define 4-6 scoring dimensions relevant to your sales motion
Week 2: Build Analysis
- Create analysis prompt (customize example above)
- Test on 10-20 historical calls
- Refine scoring based on feedback
Week 3: Deploy Feedback
- Set up delivery mechanism (Slack, email, etc.)
- Create feedback templates
- Launch with 2-3 volunteer reps
Week 4: Scale
- Roll out to full team
- Implement tracking dashboard
- Schedule weekly coaching reviews
Try our AI Lead Generator — find verified LinkedIn leads for any company instantly. No signup required.
The Competitive Advantage
Companies using AI coaching see:
- 40% faster ramp for new reps
- 15% higher quota attainment across team
- 25% reduction in rep turnover (better development = happier reps)
Your competitors are building this capability now. Every month you wait is a month they're pulling ahead.
Start building.
Want to see how MarketBetter helps sales teams optimize their outreach with AI-powered insights?